

How To Create Hadoop Cluster In Google Cloud
Launch a Hadoop-Hive-Spark (DataProc) Cluster in less than 2 Minutes on Google Cloud Platform
![]()
Overview:
Launching a Hadoop cluster can be a daunting task. It demands more than a day per node to launch a working cluster or a day to set up the Local VM Sandbox. VM Sandbox is highly susceptible to frequent crashes and corruption every now and then. We can leverage the cloud platform to solve this problem. This will make the developer's life a little easier.
Google Cloud Dataproc is Google's version of the Hadoop ecosystem. It includes the Hadoop Distributed File System (HDFS) and Map/Reduce processing framework. The Google Cloud Dataproc system also includes a number of applications such as Hive, Mahout, Pig, Spark, and Hue built on top of Hadoop.
In this blog, we will see how to set up DataProc on GCP. There are two ways to create DataProc Cluster; one is using the UI wizard and the second is using the REST/CURL command.
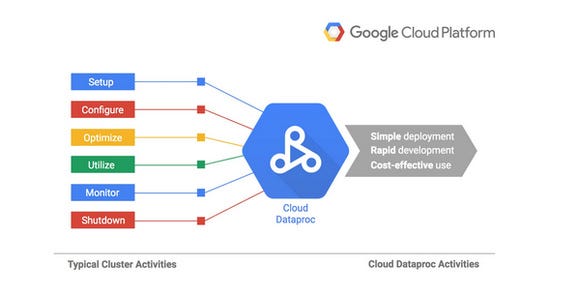
Steps to Setup Google Data Proc :
- Click here to learn how to create your first Google Cloud Project
- Click on the Menu and navigate to Dataproc under the BIG DATA section
- Click the Create cluster button
- Give the cluster a name
- Optional Step — Create a Cloud Storage staging bucket to stage files such as Hadoop jars, between client machines and the cluster. If not specified, it uses a default bucket
- Optional Step—Create a Network for the Data Proc cluster which will be used by the Compute Engine. If not specified, the default network will be chosen for you
- Set your specific Machine type for your Master node(s) and Primary disk size (For dev config =>disk size:100 GB and RAM:18 GB)
- Set your specific Machine type for your Worker node(s) and specify how many nodes you require (For dev config => 2 Worker nodes, disk size:100 GB and RAM:12 GB)
- Click on the Create button to create the cluster when you are done
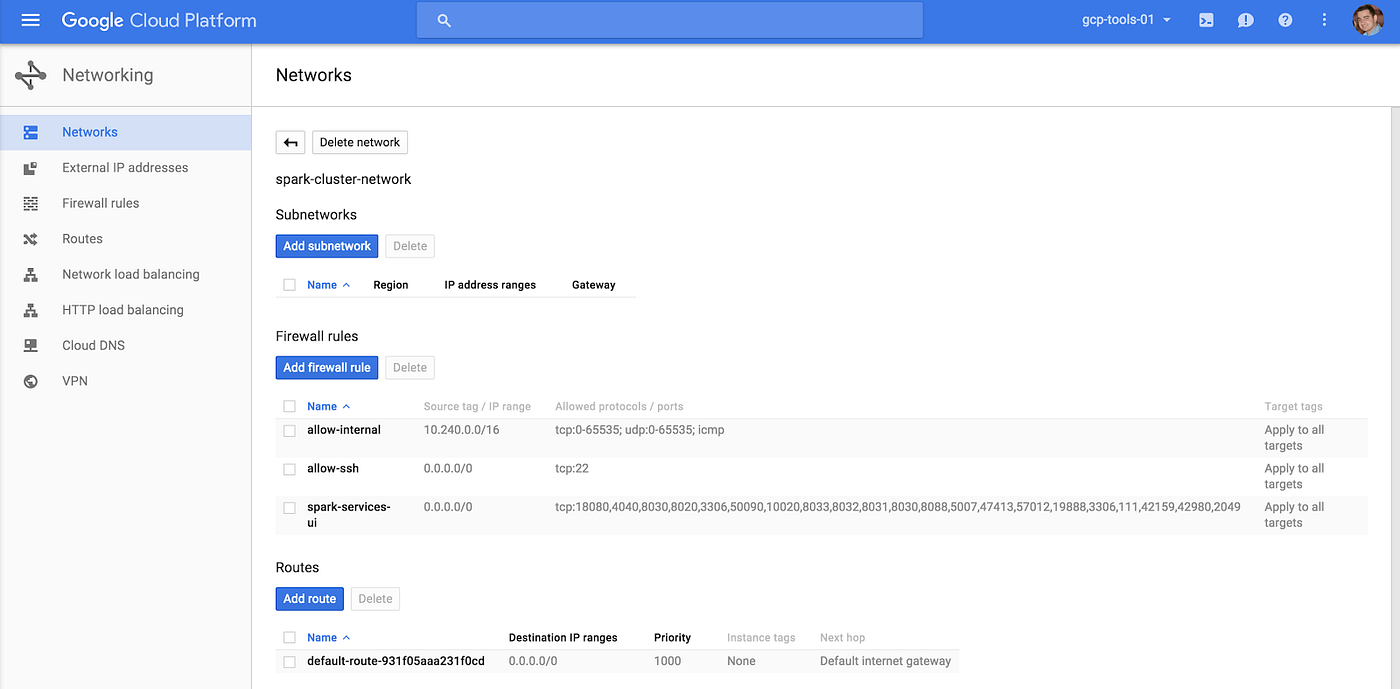
Creating Data Proc Cluster using Web UI
Creating Data Proc Cluster using Curl Command:
gcloud dataproc clusters create hadoop-hive-spark-dev-local-cluster — region us-west1 — subnet default — zone us-west1-a — master-machine-type custom-6–18432 — master-boot-disk-size 100 — num-workers 2 — worker-machine-type custom-4–12288 — worker-boot-disk-size 100 — num-worker-local-ssds 1 — image-version 1.3 — scopes ' https://www.googleapis.com/auth/cloud-platform ' — project hdp-multi-node-cluster-207321
Accessing Name Node and RM UI:
- http://xx.xx.xx.xx:8088/cluster (Change External IP with your VM Instance External IP)
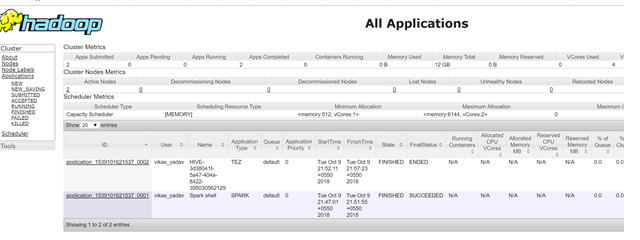
http://xx.xx.xx.xx:9870/dfshealth.html#tab-datanode
Limitations of DataProc:
- No choice of selecting a specific version of Hadoop/hive/spark stack
- You cannot pause/stop Data Proc Cluster
- No UI for managing cluster-specific configuration like Ambari/Cloudera Manager
Hope this blog helps you set up your DataProc Cluster with ease. In case of any queries, please leave a comment below and we will revert asap.
Happy coding!
About us: Clairvoyant is a data and decision engineering company. We design, implement and operate data management platforms with the aim to deliver transformative business values to our customers.
How To Create Hadoop Cluster In Google Cloud
Source: https://blog.clairvoyantsoft.com/hadoop-hive-spark-dataproc-cluster-in-less-then-2-minutes-on-google-cloud-platform-5c26d25cd56b
Posted by: harrisonsiquene.blogspot.com
0 Response to "How To Create Hadoop Cluster In Google Cloud"
Post a Comment